diff --git a/go.mod b/go.mod
index 2a0f9288a..322bd02ff 100644
--- a/go.mod
+++ b/go.mod
@@ -26,7 +26,7 @@ require (
github.com/gin-gonic/gin v1.9.0
github.com/go-fed/httpsig v1.1.0
github.com/go-playground/form/v4 v4.2.0
- github.com/go-playground/validator/v10 v10.13.0
+ github.com/go-playground/validator/v10 v10.14.0
github.com/google/uuid v1.3.0
github.com/gorilla/feeds v1.1.1
github.com/gorilla/websocket v1.5.0
@@ -99,6 +99,7 @@ require (
github.com/dsoprea/go-utility/v2 v2.0.0-20200717064901-2fccff4aa15e // indirect
github.com/dustin/go-humanize v1.0.1 // indirect
github.com/fsnotify/fsnotify v1.6.0 // indirect
+ github.com/gabriel-vasile/mimetype v1.4.2 // indirect
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/go-errors/errors v1.4.1 // indirect
github.com/go-jose/go-jose/v3 v3.0.0 // indirect
@@ -129,7 +130,7 @@ require (
github.com/kballard/go-shellquote v0.0.0-20180428030007-95032a82bc51 // indirect
github.com/klauspost/compress v1.16.3 // indirect
github.com/klauspost/cpuid/v2 v2.2.4 // indirect
- github.com/leodido/go-urn v1.2.3 // indirect
+ github.com/leodido/go-urn v1.2.4 // indirect
github.com/magiconair/properties v1.8.7 // indirect
github.com/mattn/go-isatty v0.0.18 // indirect
github.com/minio/md5-simd v1.1.2 // indirect
diff --git a/go.sum b/go.sum
index 3e45a7985..f40867f23 100644
--- a/go.sum
+++ b/go.sum
@@ -188,6 +188,8 @@ github.com/fsnotify/fsnotify v1.4.9/go.mod h1:znqG4EE+3YCdAaPaxE2ZRY/06pZUdp0tY4
github.com/fsnotify/fsnotify v1.6.0 h1:n+5WquG0fcWoWp6xPWfHdbskMCQaFnG6PfBrh1Ky4HY=
github.com/fsnotify/fsnotify v1.6.0/go.mod h1:sl3t1tCWJFWoRz9R8WJCbQihKKwmorjAbSClcnxKAGw=
github.com/fxamacker/cbor v1.5.1 h1:XjQWBgdmQyqimslUh5r4tUGmoqzHmBFQOImkWGi2awg=
+github.com/gabriel-vasile/mimetype v1.4.2 h1:w5qFW6JKBz9Y393Y4q372O9A7cUSequkh1Q7OhCmWKU=
+github.com/gabriel-vasile/mimetype v1.4.2/go.mod h1:zApsH/mKG4w07erKIaJPFiX0Tsq9BFQgN3qGY5GnNgA=
github.com/gavv/httpexpect v2.0.0+incompatible h1:1X9kcRshkSKEjNJJxX9Y9mQ5BRfbxU5kORdjhlA1yX8=
github.com/gavv/httpexpect v2.0.0+incompatible/go.mod h1:x+9tiU1YnrOvnB725RkpoLv1M62hOWzwo5OXotisrKc=
github.com/ghodss/yaml v1.0.0/go.mod h1:4dBDuWmgqj2HViK6kFavaiC9ZROes6MMH2rRYeMEF04=
@@ -230,8 +232,8 @@ github.com/go-playground/universal-translator v0.18.0/go.mod h1:UvRDBj+xPUEGrFYl
github.com/go-playground/universal-translator v0.18.1 h1:Bcnm0ZwsGyWbCzImXv+pAJnYK9S473LQFuzCbDbfSFY=
github.com/go-playground/universal-translator v0.18.1/go.mod h1:xekY+UJKNuX9WP91TpwSH2VMlDf28Uj24BCp08ZFTUY=
github.com/go-playground/validator/v10 v10.10.0/go.mod h1:74x4gJWsvQexRdW8Pn3dXSGrTK4nAUsbPlLADvpJkos=
-github.com/go-playground/validator/v10 v10.13.0 h1:cFRQdfaSMCOSfGCCLB20MHvuoHb/s5G8L5pu2ppK5AQ=
-github.com/go-playground/validator/v10 v10.13.0/go.mod h1:dwu7+CG8/CtBiJFZDz4e+5Upb6OLw04gtBYw0mcG/z4=
+github.com/go-playground/validator/v10 v10.14.0 h1:vgvQWe3XCz3gIeFDm/HnTIbj6UGmg/+t63MyGU2n5js=
+github.com/go-playground/validator/v10 v10.14.0/go.mod h1:9iXMNT7sEkjXb0I+enO7QXmzG6QCsPWY4zveKFVRSyU=
github.com/go-session/session v3.1.2+incompatible/go.mod h1:8B3iivBQjrz/JtC68Np2T1yBBLxTan3mn/3OM0CyRt0=
github.com/go-stack/stack v1.8.0/go.mod h1:v0f6uXyyMGvRgIKkXu+yp6POWl0qKG85gN/melR3HDY=
github.com/go-test/deep v1.0.8 h1:TDsG77qcSprGbC6vTN8OuXp5g+J+b5Pcguhf7Zt61VM=
@@ -427,8 +429,8 @@ github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
github.com/kr/text v0.2.0 h1:5Nx0Ya0ZqY2ygV366QzturHI13Jq95ApcVaJBhpS+AY=
github.com/kr/text v0.2.0/go.mod h1:eLer722TekiGuMkidMxC/pM04lWEeraHUUmBw8l2grE=
github.com/leodido/go-urn v1.2.1/go.mod h1:zt4jvISO2HfUBqxjfIshjdMTYS56ZS/qv49ictyFfxY=
-github.com/leodido/go-urn v1.2.3 h1:6BE2vPT0lqoz3fmOesHZiaiFh7889ssCo2GMvLCfiuA=
-github.com/leodido/go-urn v1.2.3/go.mod h1:7ZrI8mTSeBSHl/UaRyKQW1qZeMgak41ANeCNaVckg+4=
+github.com/leodido/go-urn v1.2.4 h1:XlAE/cm/ms7TE/VMVoduSpNBoyc2dOxHs5MZSwAN63Q=
+github.com/leodido/go-urn v1.2.4/go.mod h1:7ZrI8mTSeBSHl/UaRyKQW1qZeMgak41ANeCNaVckg+4=
github.com/lib/pq v1.0.0/go.mod h1:5WUZQaWbwv1U+lTReE5YruASi9Al49XbQIvNi/34Woo=
github.com/lib/pq v1.1.0/go.mod h1:5WUZQaWbwv1U+lTReE5YruASi9Al49XbQIvNi/34Woo=
github.com/lib/pq v1.2.0/go.mod h1:5WUZQaWbwv1U+lTReE5YruASi9Al49XbQIvNi/34Woo=
diff --git a/vendor/github.com/gabriel-vasile/mimetype/.gitattributes b/vendor/github.com/gabriel-vasile/mimetype/.gitattributes
new file mode 100644
index 000000000..0cc26ec01
--- /dev/null
+++ b/vendor/github.com/gabriel-vasile/mimetype/.gitattributes
@@ -0,0 +1 @@
+testdata/* linguist-vendored
diff --git a/vendor/github.com/gabriel-vasile/mimetype/CODE_OF_CONDUCT.md b/vendor/github.com/gabriel-vasile/mimetype/CODE_OF_CONDUCT.md
new file mode 100644
index 000000000..8479cd87d
--- /dev/null
+++ b/vendor/github.com/gabriel-vasile/mimetype/CODE_OF_CONDUCT.md
@@ -0,0 +1,76 @@
+# Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+In the interest of fostering an open and welcoming environment, we as
+contributors and maintainers pledge to making participation in our project and
+our community a harassment-free experience for everyone, regardless of age, body
+size, disability, ethnicity, sex characteristics, gender identity and expression,
+level of experience, education, socio-economic status, nationality, personal
+appearance, race, religion, or sexual identity and orientation.
+
+## Our Standards
+
+Examples of behavior that contributes to creating a positive environment
+include:
+
+* Using welcoming and inclusive language
+* Being respectful of differing viewpoints and experiences
+* Gracefully accepting constructive criticism
+* Focusing on what is best for the community
+* Showing empathy towards other community members
+
+Examples of unacceptable behavior by participants include:
+
+* The use of sexualized language or imagery and unwelcome sexual attention or
+ advances
+* Trolling, insulting/derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or electronic
+ address, without explicit permission
+* Other conduct which could reasonably be considered inappropriate in a
+ professional setting
+
+## Our Responsibilities
+
+Project maintainers are responsible for clarifying the standards of acceptable
+behavior and are expected to take appropriate and fair corrective action in
+response to any instances of unacceptable behavior.
+
+Project maintainers have the right and responsibility to remove, edit, or
+reject comments, commits, code, wiki edits, issues, and other contributions
+that are not aligned to this Code of Conduct, or to ban temporarily or
+permanently any contributor for other behaviors that they deem inappropriate,
+threatening, offensive, or harmful.
+
+## Scope
+
+This Code of Conduct applies both within project spaces and in public spaces
+when an individual is representing the project or its community. Examples of
+representing a project or community include using an official project e-mail
+address, posting via an official social media account, or acting as an appointed
+representative at an online or offline event. Representation of a project may be
+further defined and clarified by project maintainers.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported by contacting the project team at vasile.gabriel@email.com. All
+complaints will be reviewed and investigated and will result in a response that
+is deemed necessary and appropriate to the circumstances. The project team is
+obligated to maintain confidentiality with regard to the reporter of an incident.
+Further details of specific enforcement policies may be posted separately.
+
+Project maintainers who do not follow or enforce the Code of Conduct in good
+faith may face temporary or permanent repercussions as determined by other
+members of the project's leadership.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
+available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
+
+[homepage]: https://www.contributor-covenant.org
+
+For answers to common questions about this code of conduct, see
+https://www.contributor-covenant.org/faq
diff --git a/vendor/github.com/gabriel-vasile/mimetype/CONTRIBUTING.md b/vendor/github.com/gabriel-vasile/mimetype/CONTRIBUTING.md
new file mode 100644
index 000000000..56ae4e57c
--- /dev/null
+++ b/vendor/github.com/gabriel-vasile/mimetype/CONTRIBUTING.md
@@ -0,0 +1,12 @@
+## Contribute
+Contributions to **mimetype** are welcome. If you find an issue and you consider
+contributing, you can use the [Github issues tracker](https://github.com/gabriel-vasile/mimetype/issues)
+in order to report it, or better yet, open a pull request.
+
+Code contributions must respect these rules:
+ - code must be test covered
+ - code must be formatted using gofmt tool
+ - exported names must be documented
+
+**Important**: By submitting a pull request, you agree to allow the project
+owner to license your work under the same license as that used by the project.
diff --git a/vendor/github.com/gabriel-vasile/mimetype/LICENSE b/vendor/github.com/gabriel-vasile/mimetype/LICENSE
new file mode 100644
index 000000000..6aac070c7
--- /dev/null
+++ b/vendor/github.com/gabriel-vasile/mimetype/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2018-2020 Gabriel Vasile
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/vendor/github.com/gabriel-vasile/mimetype/README.md b/vendor/github.com/gabriel-vasile/mimetype/README.md
new file mode 100644
index 000000000..d310928de
--- /dev/null
+++ b/vendor/github.com/gabriel-vasile/mimetype/README.md
@@ -0,0 +1,108 @@
+
+ mimetype
+
+
+
+ A package for detecting MIME types and extensions based on magic numbers
+
+
+ Goroutine safe, extensible, no C bindings
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+## Features
+- fast and precise MIME type and file extension detection
+- long list of [supported MIME types](supported_mimes.md)
+- possibility to [extend](https://pkg.go.dev/github.com/gabriel-vasile/mimetype#example-package-Extend) with other file formats
+- common file formats are prioritized
+- [text vs. binary files differentiation](https://pkg.go.dev/github.com/gabriel-vasile/mimetype#example-package-TextVsBinary)
+- safe for concurrent usage
+
+## Install
+```bash
+go get github.com/gabriel-vasile/mimetype
+```
+
+## Usage
+```go
+mtype := mimetype.Detect([]byte)
+// OR
+mtype, err := mimetype.DetectReader(io.Reader)
+// OR
+mtype, err := mimetype.DetectFile("/path/to/file")
+fmt.Println(mtype.String(), mtype.Extension())
+```
+See the [runnable Go Playground examples](https://pkg.go.dev/github.com/gabriel-vasile/mimetype#pkg-overview).
+
+## Usage'
+Only use libraries like **mimetype** as a last resort. Content type detection
+using magic numbers is slow, inaccurate, and non-standard. Most of the times
+protocols have methods for specifying such metadata; e.g., `Content-Type` header
+in HTTP and SMTP.
+
+## FAQ
+Q: My file is in the list of [supported MIME types](supported_mimes.md) but
+it is not correctly detected. What should I do?
+
+A: Some file formats (often Microsoft Office documents) keep their signatures
+towards the end of the file. Try increasing the number of bytes used for detection
+with:
+```go
+mimetype.SetLimit(1024*1024) // Set limit to 1MB.
+// or
+mimetype.SetLimit(0) // No limit, whole file content used.
+mimetype.DetectFile("file.doc")
+```
+If increasing the limit does not help, please
+[open an issue](https://github.com/gabriel-vasile/mimetype/issues/new?assignees=&labels=&template=mismatched-mime-type-detected.md&title=).
+
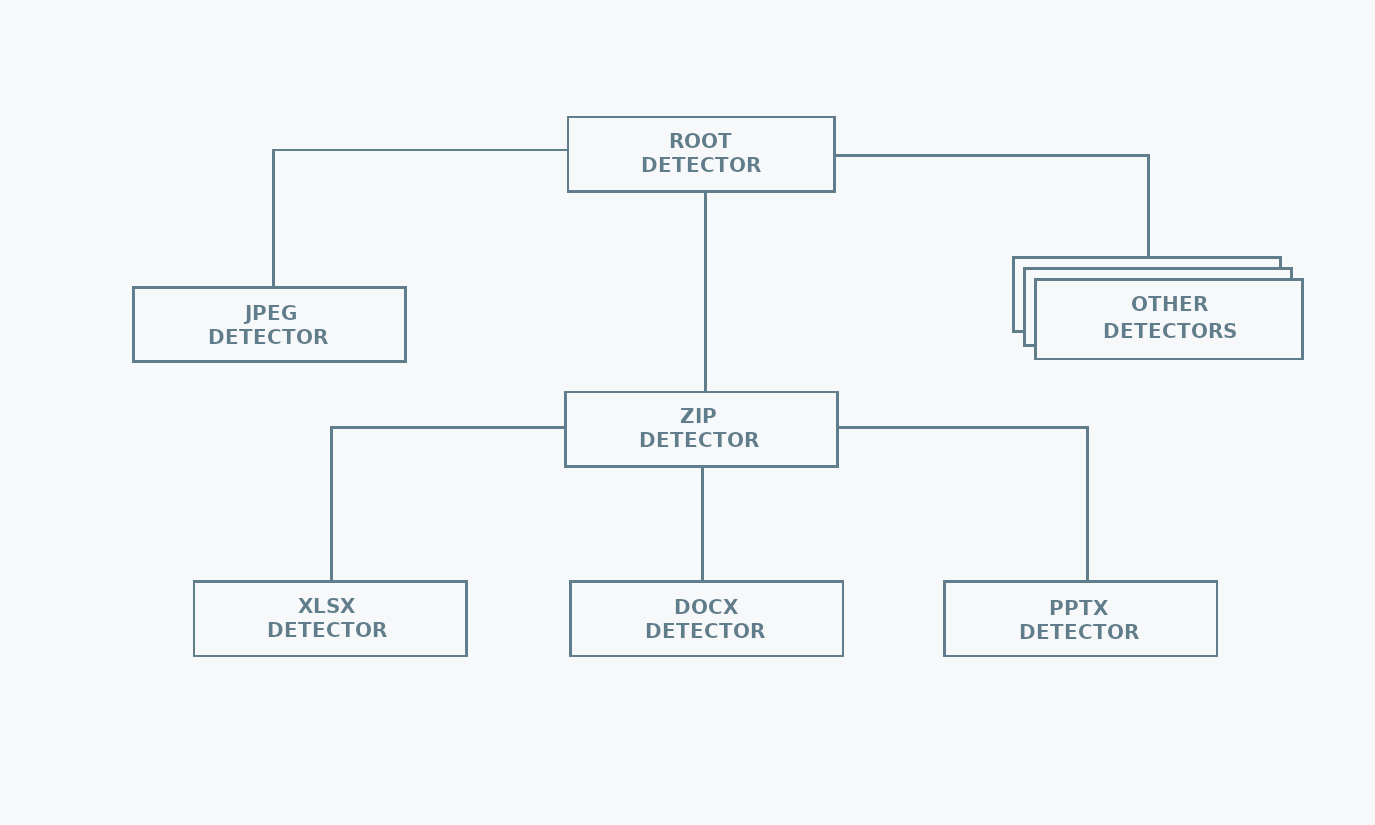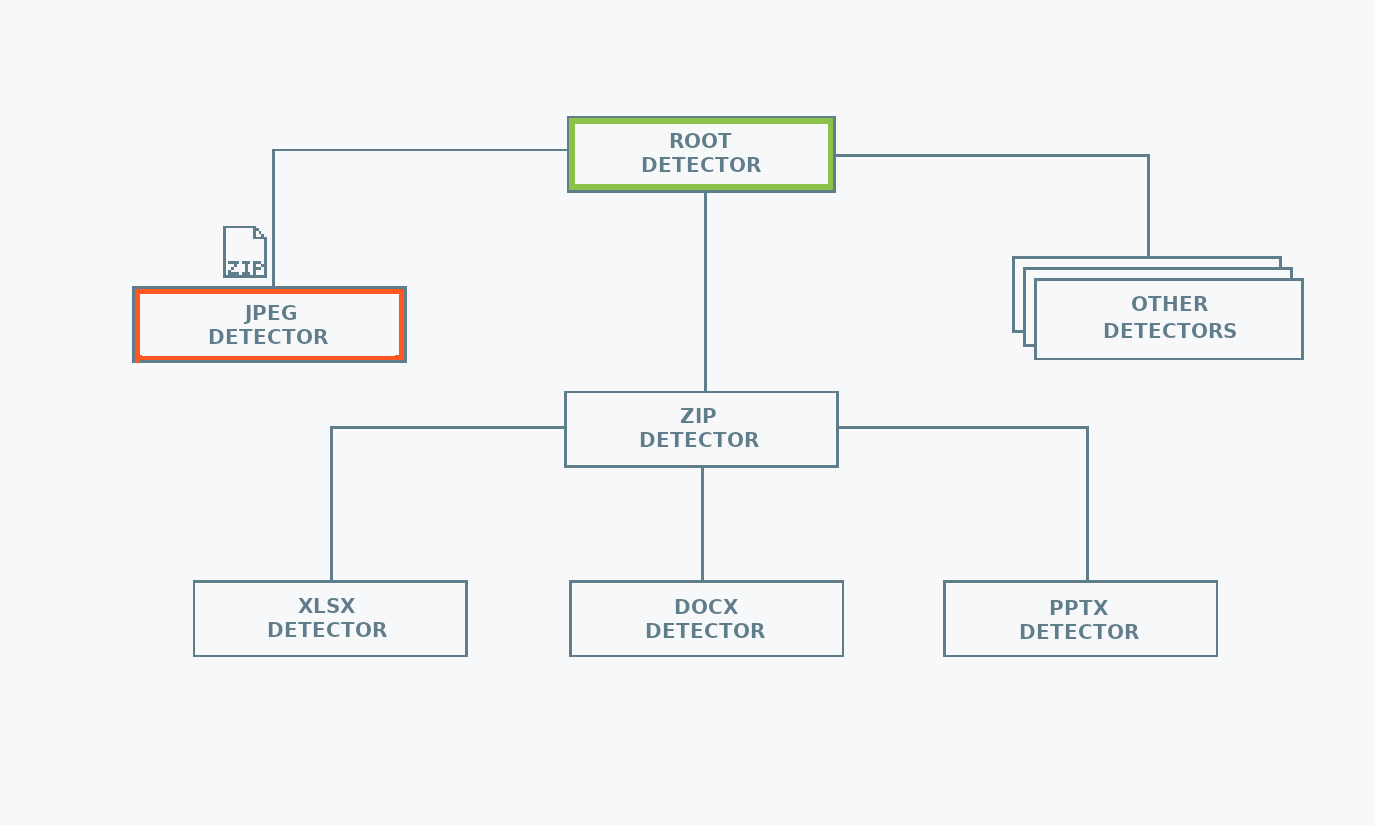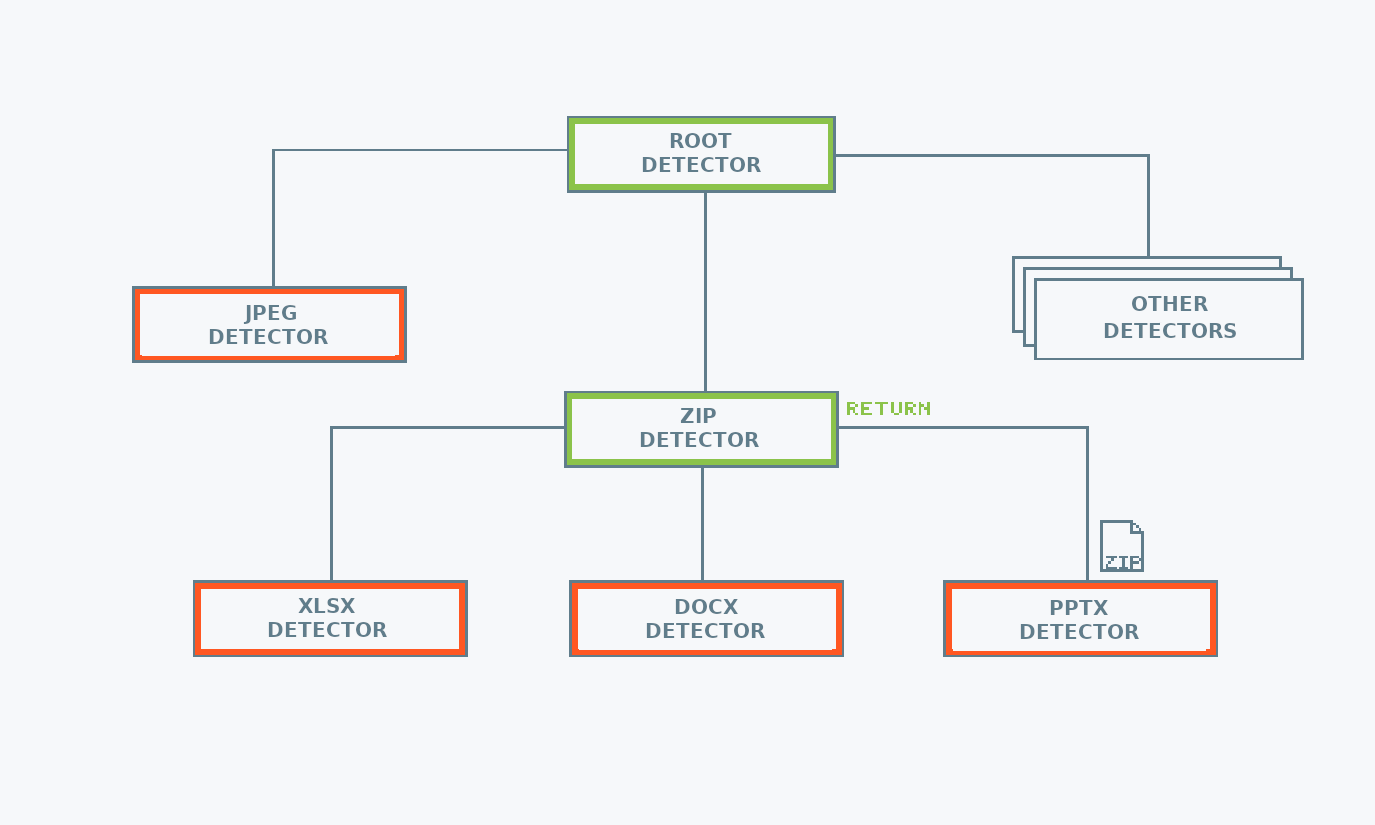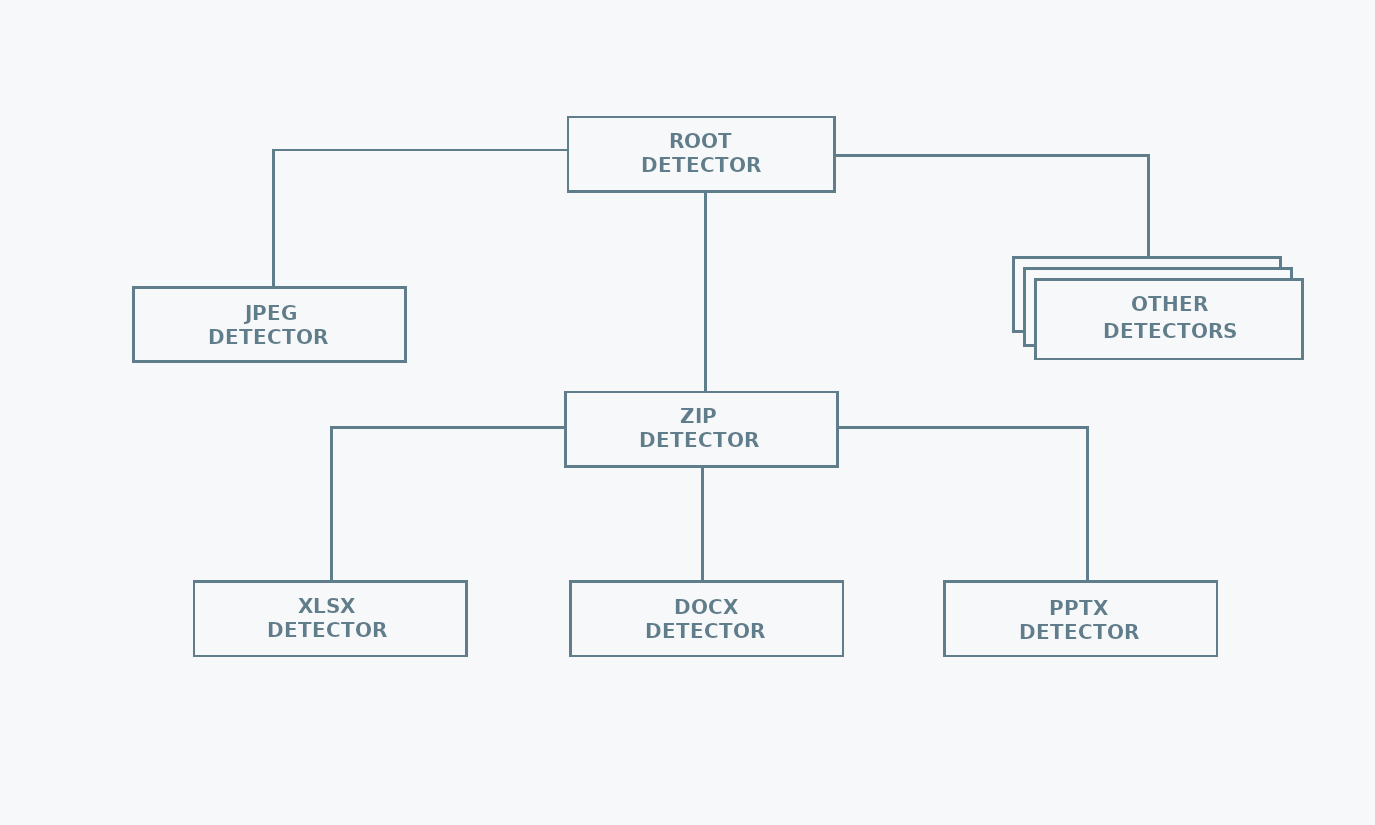
+## Structure
+**mimetype** uses a hierarchical structure to keep the MIME type detection logic.
+This reduces the number of calls needed for detecting the file type. The reason
+behind this choice is that there are file formats used as containers for other
+file formats. For example, Microsoft Office files are just zip archives,
+containing specific metadata files. Once a file has been identified as a
+zip, there is no need to check if it is a text file, but it is worth checking if
+it is an Microsoft Office file.
+
+To prevent loading entire files into memory, when detecting from a
+[reader](https://pkg.go.dev/github.com/gabriel-vasile/mimetype#DetectReader)
+or from a [file](https://pkg.go.dev/github.com/gabriel-vasile/mimetype#DetectFile)
+**mimetype** limits itself to reading only the header of the input.
+
+
+
 [](https://gitter.im/go-playground/validator?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
-
+
[](https://travis-ci.org/go-playground/validator)
[](https://coveralls.io/github/go-playground/validator?branch=master)
[](https://goreportcard.com/report/github.com/go-playground/validator)
@@ -228,6 +228,7 @@ Baked-in Validations
| dirpath | Directory Path |
| file | Existing File |
| filepath | File Path |
+| image | Image |
| isdefault | Is Default |
| len | Length |
| max | Maximum |
diff --git a/vendor/github.com/go-playground/validator/v10/baked_in.go b/vendor/github.com/go-playground/validator/v10/baked_in.go
index d66980b6e..8e6b169cb 100644
--- a/vendor/github.com/go-playground/validator/v10/baked_in.go
+++ b/vendor/github.com/go-playground/validator/v10/baked_in.go
@@ -22,6 +22,7 @@ import (
"golang.org/x/crypto/sha3"
"golang.org/x/text/language"
+ "github.com/gabriel-vasile/mimetype"
"github.com/leodido/go-urn"
)
@@ -144,6 +145,7 @@ var (
"endswith": endsWith,
"startsnotwith": startsNotWith,
"endsnotwith": endsNotWith,
+ "image": isImage,
"isbn": isISBN,
"isbn10": isISBN10,
"isbn13": isISBN13,
@@ -1488,6 +1490,67 @@ func isFile(fl FieldLevel) bool {
panic(fmt.Sprintf("Bad field type %T", field.Interface()))
}
+// isImage is the validation function for validating if the current field's value contains the path to a valid image file
+func isImage(fl FieldLevel) bool {
+ mimetypes := map[string]bool{
+ "image/bmp": true,
+ "image/cis-cod": true,
+ "image/gif": true,
+ "image/ief": true,
+ "image/jpeg": true,
+ "image/jp2": true,
+ "image/jpx": true,
+ "image/jpm": true,
+ "image/pipeg": true,
+ "image/png": true,
+ "image/svg+xml": true,
+ "image/tiff": true,
+ "image/webp": true,
+ "image/x-cmu-raster": true,
+ "image/x-cmx": true,
+ "image/x-icon": true,
+ "image/x-portable-anymap": true,
+ "image/x-portable-bitmap": true,
+ "image/x-portable-graymap": true,
+ "image/x-portable-pixmap": true,
+ "image/x-rgb": true,
+ "image/x-xbitmap": true,
+ "image/x-xpixmap": true,
+ "image/x-xwindowdump": true,
+ }
+ field := fl.Field()
+
+ switch field.Kind() {
+ case reflect.String:
+ filePath := field.String()
+ fileInfo, err := os.Stat(filePath)
+
+ if err != nil {
+ return false
+ }
+
+ if fileInfo.IsDir() {
+ return false
+ }
+
+ file, err := os.Open(filePath)
+ if err != nil {
+ return false
+ }
+ defer file.Close()
+
+ mime, err := mimetype.DetectReader(file)
+ if err != nil {
+ return false
+ }
+
+ if _, ok := mimetypes[mime.String()]; ok {
+ return true
+ }
+ }
+ return false
+}
+
// isFilePath is the validation function for validating if the current field's value is a valid file path.
func isFilePath(fl FieldLevel) bool {
diff --git a/vendor/github.com/go-playground/validator/v10/country_codes.go b/vendor/github.com/go-playground/validator/v10/country_codes.go
index 91b2e0b90..0119f0574 100644
--- a/vendor/github.com/go-playground/validator/v10/country_codes.go
+++ b/vendor/github.com/go-playground/validator/v10/country_codes.go
@@ -1135,7 +1135,7 @@ var iso3166_2 = map[string]bool{
"VN-69": true, "VN-70": true, "VN-71": true, "VN-72": true, "VN-73": true,
"VN-CT": true, "VN-DN": true, "VN-HN": true, "VN-HP": true, "VN-SG": true,
"VU-MAP": true, "VU-PAM": true, "VU-SAM": true, "VU-SEE": true, "VU-TAE": true,
- "VU-TOB": true, "WF-SG": true,"WF-UV": true, "WS-AA": true, "WS-AL": true, "WS-AT": true, "WS-FA": true,
+ "VU-TOB": true, "WF-SG": true, "WF-UV": true, "WS-AA": true, "WS-AL": true, "WS-AT": true, "WS-FA": true,
"WS-GE": true, "WS-GI": true, "WS-PA": true, "WS-SA": true, "WS-TU": true,
"WS-VF": true, "WS-VS": true, "YE-AB": true, "YE-AD": true, "YE-AM": true,
"YE-BA": true, "YE-DA": true, "YE-DH": true, "YE-HD": true, "YE-HJ": true, "YE-HU": true,
diff --git a/vendor/github.com/go-playground/validator/v10/doc.go b/vendor/github.com/go-playground/validator/v10/doc.go
index f31a7d538..f5aa9e523 100644
--- a/vendor/github.com/go-playground/validator/v10/doc.go
+++ b/vendor/github.com/go-playground/validator/v10/doc.go
@@ -863,7 +863,6 @@ This validates that a string value is a valid JWT
Usage: jwt
-
# File
This validates that a string value contains a valid file path and that
@@ -872,6 +871,15 @@ This is done using os.Stat, which is a platform independent function.
Usage: file
+# Image path
+
+This validates that a string value contains a valid file path and that
+the file exists on the machine and is an image.
+This is done using os.Stat and github.com/gabriel-vasile/mimetype
+
+ Usage: image
+
+# URL String
# File Path
@@ -881,7 +889,6 @@ This is done using os.Stat, which is a platform independent function.
Usage: filepath
-
# URL String
This validates that a string value contains a valid url
@@ -923,7 +930,6 @@ you can use this with the omitempty tag.
Usage: base64url
-
# Base64RawURL String
This validates that a string value contains a valid base64 URL safe value,
@@ -934,7 +940,6 @@ you can use this with the omitempty tag.
Usage: base64url
-
# Bitcoin Address
This validates that a string value contains a valid bitcoin address.
@@ -1267,7 +1272,6 @@ This is done using os.Stat, which is a platform independent function.
Usage: dir
-
# Directory Path
This validates that a string value contains a valid directory but does
@@ -1278,7 +1282,6 @@ may not exist at the time of validation.
Usage: dirpath
-
# HostPort
This validates that a string value contains a valid DNS hostname and port that
@@ -1350,7 +1353,6 @@ More information on https://semver.org/
Usage: semver
-
# CVE Identifier
This validates that a string value is a valid cve id, defined in cve mitre.
@@ -1358,17 +1360,15 @@ More information on https://cve.mitre.org/
Usage: cve
-
# Credit Card
This validates that a string value contains a valid credit card number using Luhn algorithm.
Usage: credit_card
-
# Luhn Checksum
- Usage: luhn_checksum
+ Usage: luhn_checksum
This validates that a string or (u)int value contains a valid checksum using the Luhn algorithm.
@@ -1376,8 +1376,7 @@ This validates that a string or (u)int value contains a valid checksum using the
This validates that a string is a valid 24 character hexadecimal string.
- Usage: mongodb
-
+ Usage: mongodb
# Cron
@@ -1385,7 +1384,7 @@ This validates that a string value contains a valid cron expression.
Usage: cron
-Alias Validators and Tags
+# Alias Validators and Tags
Alias Validators and Tags
NOTE: When returning an error, the tag returned in "FieldError" will be
diff --git a/vendor/github.com/leodido/go-urn/machine.go b/vendor/github.com/leodido/go-urn/machine.go
index fe5a0cc86..f8d57b412 100644
--- a/vendor/github.com/leodido/go-urn/machine.go
+++ b/vendor/github.com/leodido/go-urn/machine.go
@@ -61,11 +61,9 @@ func (m *machine) Parse(input []byte) (*URN, error) {
m.err = nil
m.tolower = []int{}
output := &URN{}
-
{
m.cs = start
}
-
{
if (m.p) == (m.pe) {
goto _testEof
@@ -1674,7 +1672,6 @@ func (m *machine) Parse(input []byte) (*URN, error) {
{
goto st46
}
-
}
}
diff --git a/vendor/github.com/leodido/go-urn/makefile b/vendor/github.com/leodido/go-urn/makefile
index d088c044e..df87cdc6d 100644
--- a/vendor/github.com/leodido/go-urn/makefile
+++ b/vendor/github.com/leodido/go-urn/makefile
@@ -17,7 +17,7 @@ images: docs/urn.png
.PHONY: removecomments
removecomments:
- @cd ./tools/removecomments; go build -o ../../removecomments ./main.go
+ @cd ./tools/removecomments; go build -o ../../removecomments .
machine.go: machine.go.rl
@@ -50,4 +50,4 @@ snake2camel:
while ( match($$0, /(.*)([a-z]+[0-9]*)_([a-zA-Z0-9])(.*)/, cap) ) \
$$0 = cap[1] cap[2] toupper(cap[3]) cap[4]; \
print \
- }' $(file)
\ No newline at end of file
+ }' $(file)
diff --git a/vendor/modules.txt b/vendor/modules.txt
index 9f65c46bf..3f3da4ce0 100644
--- a/vendor/modules.txt
+++ b/vendor/modules.txt
@@ -174,6 +174,12 @@ github.com/dustin/go-humanize
# github.com/fsnotify/fsnotify v1.6.0
## explicit; go 1.16
github.com/fsnotify/fsnotify
+# github.com/gabriel-vasile/mimetype v1.4.2
+## explicit; go 1.20
+github.com/gabriel-vasile/mimetype
+github.com/gabriel-vasile/mimetype/internal/charset
+github.com/gabriel-vasile/mimetype/internal/json
+github.com/gabriel-vasile/mimetype/internal/magic
# github.com/gin-contrib/cors v1.4.0
## explicit; go 1.13
github.com/gin-contrib/cors
@@ -222,7 +228,7 @@ github.com/go-playground/locales/currency
# github.com/go-playground/universal-translator v0.18.1
## explicit; go 1.18
github.com/go-playground/universal-translator
-# github.com/go-playground/validator/v10 v10.13.0
+# github.com/go-playground/validator/v10 v10.14.0
## explicit; go 1.18
github.com/go-playground/validator/v10
# github.com/go-xmlfmt/xmlfmt v0.0.0-20211206191508-7fd73a941850
@@ -359,7 +365,7 @@ github.com/klauspost/compress/zlib
# github.com/klauspost/cpuid/v2 v2.2.4
## explicit; go 1.15
github.com/klauspost/cpuid/v2
-# github.com/leodido/go-urn v1.2.3
+# github.com/leodido/go-urn v1.2.4
## explicit; go 1.16
github.com/leodido/go-urn
# github.com/magiconair/properties v1.8.7
[](https://gitter.im/go-playground/validator?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
-
+
[](https://travis-ci.org/go-playground/validator)
[](https://coveralls.io/github/go-playground/validator?branch=master)
[](https://goreportcard.com/report/github.com/go-playground/validator)
@@ -228,6 +228,7 @@ Baked-in Validations
| dirpath | Directory Path |
| file | Existing File |
| filepath | File Path |
+| image | Image |
| isdefault | Is Default |
| len | Length |
| max | Maximum |
diff --git a/vendor/github.com/go-playground/validator/v10/baked_in.go b/vendor/github.com/go-playground/validator/v10/baked_in.go
index d66980b6e..8e6b169cb 100644
--- a/vendor/github.com/go-playground/validator/v10/baked_in.go
+++ b/vendor/github.com/go-playground/validator/v10/baked_in.go
@@ -22,6 +22,7 @@ import (
"golang.org/x/crypto/sha3"
"golang.org/x/text/language"
+ "github.com/gabriel-vasile/mimetype"
"github.com/leodido/go-urn"
)
@@ -144,6 +145,7 @@ var (
"endswith": endsWith,
"startsnotwith": startsNotWith,
"endsnotwith": endsNotWith,
+ "image": isImage,
"isbn": isISBN,
"isbn10": isISBN10,
"isbn13": isISBN13,
@@ -1488,6 +1490,67 @@ func isFile(fl FieldLevel) bool {
panic(fmt.Sprintf("Bad field type %T", field.Interface()))
}
+// isImage is the validation function for validating if the current field's value contains the path to a valid image file
+func isImage(fl FieldLevel) bool {
+ mimetypes := map[string]bool{
+ "image/bmp": true,
+ "image/cis-cod": true,
+ "image/gif": true,
+ "image/ief": true,
+ "image/jpeg": true,
+ "image/jp2": true,
+ "image/jpx": true,
+ "image/jpm": true,
+ "image/pipeg": true,
+ "image/png": true,
+ "image/svg+xml": true,
+ "image/tiff": true,
+ "image/webp": true,
+ "image/x-cmu-raster": true,
+ "image/x-cmx": true,
+ "image/x-icon": true,
+ "image/x-portable-anymap": true,
+ "image/x-portable-bitmap": true,
+ "image/x-portable-graymap": true,
+ "image/x-portable-pixmap": true,
+ "image/x-rgb": true,
+ "image/x-xbitmap": true,
+ "image/x-xpixmap": true,
+ "image/x-xwindowdump": true,
+ }
+ field := fl.Field()
+
+ switch field.Kind() {
+ case reflect.String:
+ filePath := field.String()
+ fileInfo, err := os.Stat(filePath)
+
+ if err != nil {
+ return false
+ }
+
+ if fileInfo.IsDir() {
+ return false
+ }
+
+ file, err := os.Open(filePath)
+ if err != nil {
+ return false
+ }
+ defer file.Close()
+
+ mime, err := mimetype.DetectReader(file)
+ if err != nil {
+ return false
+ }
+
+ if _, ok := mimetypes[mime.String()]; ok {
+ return true
+ }
+ }
+ return false
+}
+
// isFilePath is the validation function for validating if the current field's value is a valid file path.
func isFilePath(fl FieldLevel) bool {
diff --git a/vendor/github.com/go-playground/validator/v10/country_codes.go b/vendor/github.com/go-playground/validator/v10/country_codes.go
index 91b2e0b90..0119f0574 100644
--- a/vendor/github.com/go-playground/validator/v10/country_codes.go
+++ b/vendor/github.com/go-playground/validator/v10/country_codes.go
@@ -1135,7 +1135,7 @@ var iso3166_2 = map[string]bool{
"VN-69": true, "VN-70": true, "VN-71": true, "VN-72": true, "VN-73": true,
"VN-CT": true, "VN-DN": true, "VN-HN": true, "VN-HP": true, "VN-SG": true,
"VU-MAP": true, "VU-PAM": true, "VU-SAM": true, "VU-SEE": true, "VU-TAE": true,
- "VU-TOB": true, "WF-SG": true,"WF-UV": true, "WS-AA": true, "WS-AL": true, "WS-AT": true, "WS-FA": true,
+ "VU-TOB": true, "WF-SG": true, "WF-UV": true, "WS-AA": true, "WS-AL": true, "WS-AT": true, "WS-FA": true,
"WS-GE": true, "WS-GI": true, "WS-PA": true, "WS-SA": true, "WS-TU": true,
"WS-VF": true, "WS-VS": true, "YE-AB": true, "YE-AD": true, "YE-AM": true,
"YE-BA": true, "YE-DA": true, "YE-DH": true, "YE-HD": true, "YE-HJ": true, "YE-HU": true,
diff --git a/vendor/github.com/go-playground/validator/v10/doc.go b/vendor/github.com/go-playground/validator/v10/doc.go
index f31a7d538..f5aa9e523 100644
--- a/vendor/github.com/go-playground/validator/v10/doc.go
+++ b/vendor/github.com/go-playground/validator/v10/doc.go
@@ -863,7 +863,6 @@ This validates that a string value is a valid JWT
Usage: jwt
-
# File
This validates that a string value contains a valid file path and that
@@ -872,6 +871,15 @@ This is done using os.Stat, which is a platform independent function.
Usage: file
+# Image path
+
+This validates that a string value contains a valid file path and that
+the file exists on the machine and is an image.
+This is done using os.Stat and github.com/gabriel-vasile/mimetype
+
+ Usage: image
+
+# URL String
# File Path
@@ -881,7 +889,6 @@ This is done using os.Stat, which is a platform independent function.
Usage: filepath
-
# URL String
This validates that a string value contains a valid url
@@ -923,7 +930,6 @@ you can use this with the omitempty tag.
Usage: base64url
-
# Base64RawURL String
This validates that a string value contains a valid base64 URL safe value,
@@ -934,7 +940,6 @@ you can use this with the omitempty tag.
Usage: base64url
-
# Bitcoin Address
This validates that a string value contains a valid bitcoin address.
@@ -1267,7 +1272,6 @@ This is done using os.Stat, which is a platform independent function.
Usage: dir
-
# Directory Path
This validates that a string value contains a valid directory but does
@@ -1278,7 +1282,6 @@ may not exist at the time of validation.
Usage: dirpath
-
# HostPort
This validates that a string value contains a valid DNS hostname and port that
@@ -1350,7 +1353,6 @@ More information on https://semver.org/
Usage: semver
-
# CVE Identifier
This validates that a string value is a valid cve id, defined in cve mitre.
@@ -1358,17 +1360,15 @@ More information on https://cve.mitre.org/
Usage: cve
-
# Credit Card
This validates that a string value contains a valid credit card number using Luhn algorithm.
Usage: credit_card
-
# Luhn Checksum
- Usage: luhn_checksum
+ Usage: luhn_checksum
This validates that a string or (u)int value contains a valid checksum using the Luhn algorithm.
@@ -1376,8 +1376,7 @@ This validates that a string or (u)int value contains a valid checksum using the
This validates that a string is a valid 24 character hexadecimal string.
- Usage: mongodb
-
+ Usage: mongodb
# Cron
@@ -1385,7 +1384,7 @@ This validates that a string value contains a valid cron expression.
Usage: cron
-Alias Validators and Tags
+# Alias Validators and Tags
Alias Validators and Tags
NOTE: When returning an error, the tag returned in "FieldError" will be
diff --git a/vendor/github.com/leodido/go-urn/machine.go b/vendor/github.com/leodido/go-urn/machine.go
index fe5a0cc86..f8d57b412 100644
--- a/vendor/github.com/leodido/go-urn/machine.go
+++ b/vendor/github.com/leodido/go-urn/machine.go
@@ -61,11 +61,9 @@ func (m *machine) Parse(input []byte) (*URN, error) {
m.err = nil
m.tolower = []int{}
output := &URN{}
-
{
m.cs = start
}
-
{
if (m.p) == (m.pe) {
goto _testEof
@@ -1674,7 +1672,6 @@ func (m *machine) Parse(input []byte) (*URN, error) {
{
goto st46
}
-
}
}
diff --git a/vendor/github.com/leodido/go-urn/makefile b/vendor/github.com/leodido/go-urn/makefile
index d088c044e..df87cdc6d 100644
--- a/vendor/github.com/leodido/go-urn/makefile
+++ b/vendor/github.com/leodido/go-urn/makefile
@@ -17,7 +17,7 @@ images: docs/urn.png
.PHONY: removecomments
removecomments:
- @cd ./tools/removecomments; go build -o ../../removecomments ./main.go
+ @cd ./tools/removecomments; go build -o ../../removecomments .
machine.go: machine.go.rl
@@ -50,4 +50,4 @@ snake2camel:
while ( match($$0, /(.*)([a-z]+[0-9]*)_([a-zA-Z0-9])(.*)/, cap) ) \
$$0 = cap[1] cap[2] toupper(cap[3]) cap[4]; \
print \
- }' $(file)
\ No newline at end of file
+ }' $(file)
diff --git a/vendor/modules.txt b/vendor/modules.txt
index 9f65c46bf..3f3da4ce0 100644
--- a/vendor/modules.txt
+++ b/vendor/modules.txt
@@ -174,6 +174,12 @@ github.com/dustin/go-humanize
# github.com/fsnotify/fsnotify v1.6.0
## explicit; go 1.16
github.com/fsnotify/fsnotify
+# github.com/gabriel-vasile/mimetype v1.4.2
+## explicit; go 1.20
+github.com/gabriel-vasile/mimetype
+github.com/gabriel-vasile/mimetype/internal/charset
+github.com/gabriel-vasile/mimetype/internal/json
+github.com/gabriel-vasile/mimetype/internal/magic
# github.com/gin-contrib/cors v1.4.0
## explicit; go 1.13
github.com/gin-contrib/cors
@@ -222,7 +228,7 @@ github.com/go-playground/locales/currency
# github.com/go-playground/universal-translator v0.18.1
## explicit; go 1.18
github.com/go-playground/universal-translator
-# github.com/go-playground/validator/v10 v10.13.0
+# github.com/go-playground/validator/v10 v10.14.0
## explicit; go 1.18
github.com/go-playground/validator/v10
# github.com/go-xmlfmt/xmlfmt v0.0.0-20211206191508-7fd73a941850
@@ -359,7 +365,7 @@ github.com/klauspost/compress/zlib
# github.com/klauspost/cpuid/v2 v2.2.4
## explicit; go 1.15
github.com/klauspost/cpuid/v2
-# github.com/leodido/go-urn v1.2.3
+# github.com/leodido/go-urn v1.2.4
## explicit; go 1.16
github.com/leodido/go-urn
# github.com/magiconair/properties v1.8.7